The common pitfalls of ORM frameworks - RBAR
ORM frameworks are a great tool especially for junior developers because they allow bluring the line between the application logic and the data it crunches. Except that the aforementioned line blurring advantage may become a real production issue if not taken in consideration when writing the code.
Let us consider an example. Let's suppose we're working on a (what else?) e-commerce platform. Somewhere in the depts of that platform there is a IOrderService which exposes the following method:
public interface IOrderService
{
void PlaceOrder(Guid customerId, IEnumerable<OrderItem> itemIds)
}
where OrderItem holds the data about an ordered item.
public class OrderItem
{
public Guid ItemId { get; set; }
public int Quantity { get; set; }
}
The PlaceOrder method needs to:
- Lookup the
Customerin the database - Create a new
CustomerOrderinstance - Add each
Itemto the order and decrease stock count - Save the
CustomerOrderin the database
Of course, since we're using an ORM framework, the classes used by the repositories - Customer, CustomerOrder and Item - are mapped to database tables.
Given the above, someone would be tempted to implement the PlaceOrder method like this:
public void PlaceOrder(Guid customerId, IEnumerable<OrderItem> orderItems)
{
var customer = _customerRepository.Get(customerId);
var order = new CustomerOrder(customer);
foreach (var orderedItem in orderItems)
{
var item = _itemRepository.Get(orderedItem.ItemId);
item.DecreaseStockCount(orderedItem.Quantity);
_itemRepository.Update(item);
order.Add(orderedItem);
}
_customerOrderRepository.Register(order);
_unitOfWork.Commit();
}
And why wouldn't they? It seems the most straightforward transposition of the requirements defined above. The code behaves as expected in both Dev and QA environments and afterwards it's promoted to production where lies a database with hundreds of thousands of rows in the Items table. There also, the behavior is as expected until one day an eager customer wants to buy 980 distinct items (because why not?).
What happens with the code above? It still works well but the database command times out and the customer cannot place a significant order.
So what is the problem? Why it times out? Well, because the aforementioned line between application logic and database is blurred enough for the iterative paradigm to creep into the set-based one. In the SQL community this paradigm creep has a name - Row By Agonizing Row.
To put it in the context of the example above - it takes more time to do 980 pairs of SELECT and UPDATE operations than to do one SELECT which returns 980 rows followed by one UPDATE which alters 980 rows.
So, let's switch the paradigm and start working with collections in our code to minimize the number of operations in the database. The first thing to do is to load all items in bulk instead of loading them one by one. This will reduce the number of SELECT operations from 980 to 1 (a whooping 50% of the number of operations). We still need to update the stock counts for each item individually because the ORM framework doesn't know how to translate the changes for each item into a single UPDATE statement but considering that we've halved the total number of operations let's give this approach a try shall we?
public void PlaceOrder(Guid customerId, IEnumerable<OrderItem> orderItems)
{
var customer = _customerRepository.Get(customerId);
var customerOrder = new CustomerOrder(customer);
var items = itemRepository.Items
.Join(orderItems,
item => item.Id,
orderedItem => orderedItem.ItemId,
(item, _) => item)
.ToDictionary(i => i.Id);
foreach(var orderedItem in orderedItems)
{
var item = items[orderedItem.ItemId];
item.DecreaseStockCount(orderedItem.Quantity);
_itemRepository.Update(item);
customerOrder.Add(item);
}
_customerOrderRepository.Register(order);
_unitOfWork.Commit();
}
This will solve the problem with the timeout but will create another one - useless load on the system. The code loads 980 rows from the database but only uses two attributes of each row - Id and Barcode. We might say that this can be solved by projecting an Item into a tuple of <Barcode, Id> but this would be a partial solution because we can still place a great burden on system memory by sending an request of 10k items.
Also, there are still 980 UPDATE statements that need to be executed which is still a lot.
The best approach to this is to not load any data at all from the database and to do the processing as close to the actual data as possible.
And how can we do that? Exactly - with stored procedures.
declare procedure CreateCustomerOrder(
@customerId uniqueidentifier not null,
@orderItems udttorderitems readonly)
begin
set no_count on
update sc
set sc.Count = sc.Count - o.Quantity
from StockCounts sc
join Items i on sc.ItemId == i.Id
join @orderItems 0 on i.Id = o.ItemId
insert into CustomerOrder(CustomerId, OrderDateTime)
values (@customerId, GetDate())
insert into OrderLines(OrderId, ItemId, Quantity)
select scope_identity(), i.Id, o.Quantity
from Items i
join @orderItems o on o.ItemId = i.Id
end
Now, of course in real life situations there won't be a customer that orders almost 1000 items with a single order and the second approach (bulk load items and iterate the collection) will do just fine. The important thing to keep in mind in such cases is the need to switch from a procedural mindset to a set-based one thus pruning this phenomenon of paradigm creep which can become a full-blown RBAR processing.
Later edit
I have created a GitHub repository to showcase the first two implemetations of IOrderservice.
Python development using Emacs from terminal
A few weeks ago, while working on a hackathon project I found myself very disappointed with my progress.
I had the impression that I can do better but something is holding me back and then I realized that I was too distracted by Alt-Tab-ing through all open applications, iterating through dozens of open tabs in the browser and spending too much time on websites that were of no use at that time.
At that moment, on a whim I decided to try and eliminate all of these distractions the hard way - by not using the X server at all (I was working on Kubuntu).
Since I was mainly working with Python code and occasionally I would need to open some file for inspection and all of these were done from Emacs I said to myself:
Emacs can be opened from console so why not start working on hackathon from console?
Said and done. Ctrl-Alt-F1 and I was prompted with the TTY cursor. I logged in, started Emacs opened all the required files and started working. All good until I found myself in the situation where I needed to lookup something on the Internet. I knew I could use eww as a web browser so normally I did so (yeah, I'm one of those people that use Bing instead of Google):
M-x eww
Enter URL or keywords: www.bing.com
And nothing… Oh, wait, I remember needing to enter some username and password when connecting to the Wi-Fi but I wasn't prompted for those after logging into terminal. How do I connect to the network?
As there was no way for me to find that out without using some sort of GUI (I'm not that good with terminals) I started a new X session, connected from there to Wi-Fi and found this StackOverflow answer. So I logged back to the terminal and from Emacs started eshell with M-x eshell. From there I issued the following command
nmcli c up <wi-fi-name>
which connected me to the Wi-Fi network.
Note: I got connected because on previous sessions I opted to store the credentials for the connection; to get a prompt for username and password for the Wi-Fi use the --ask parameter like this:
nmcli --ask c up <wi-fi-name>
After connecting I resumed my coding and only at the end of the hackathon I stopped to ponder upon my experience; it wasn't as smooth as I expected. Although I consider a big plus the fact that I was able to issue shell commands within Emacs through eshell there were some hick-ups along the way.
The first thing I noticed is that under terminal not all shortcuts that are very familiar for me are available. Namely, in org-mode the combination M-right which is used for indentation, moving columns within a table and demoting list items is not available; instead I had to use either C-c C-x r shortcut or explicitly invoke the command using M-x org-meta-right. Although I did not invoke this command frequently, without the shortcut I felt like I was pulled out of the flow each time I had to use an alternative method of invoking the command.
The second and by far the biggest nuisance was the lack of proper web-browsing experience. Although I most frequently landed on StackOverflow pages and although eww rendered them pretty good (see image below) the lack of visual experience I was used to gave me a sense of discomfort.
However, when I got to analyze how much I have accomplished while working from terminal I was simply amazed. Having no distraction and meaningless motion like cycling through windows and tabs had a huge impact on my productivity. I was able to fully concentrate and immerse in the code and by doing so I had a lot of work done.
Rename multiple files with Emacs dired
While adding text files from within a folder to a project file I noticed that the files in the folder were lacking naming consistency. Namely, there were files which had the .txt extension and files without extension, as shown in the image below:
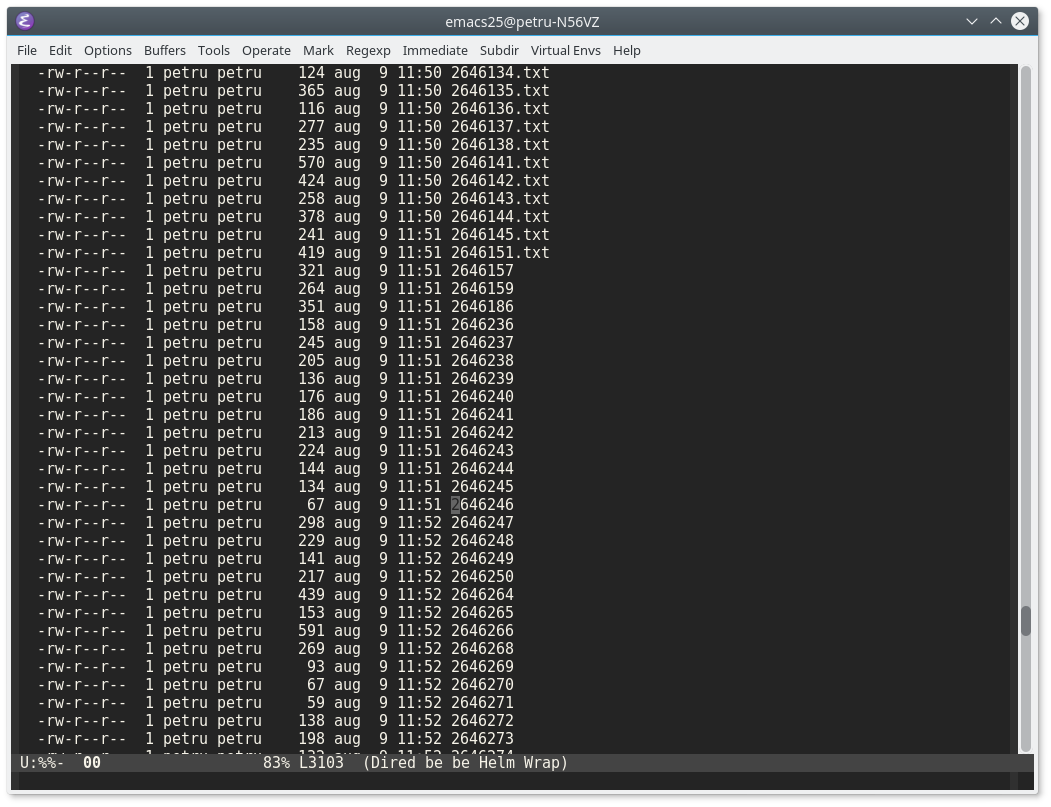
Since there were about 100 files without extension I started asking myself: Is there a way to add .txt extension to those files without manually renaming each one?
Of course there is. Here's what I did using Emacs and dired:
-
M-x diredto the desired directory (obviously) - In the
diredbuffer enter the edit mode withC-x C-q - Go to the last file that has extension before the block of files without extension.
- Starting from that file, place a mark and select the whole block of files without extension (the selection should include the last file with extension).
- Narrow to the selected region using
M-x narrow-to-regionorC-x n nThe buffer should look like the image below: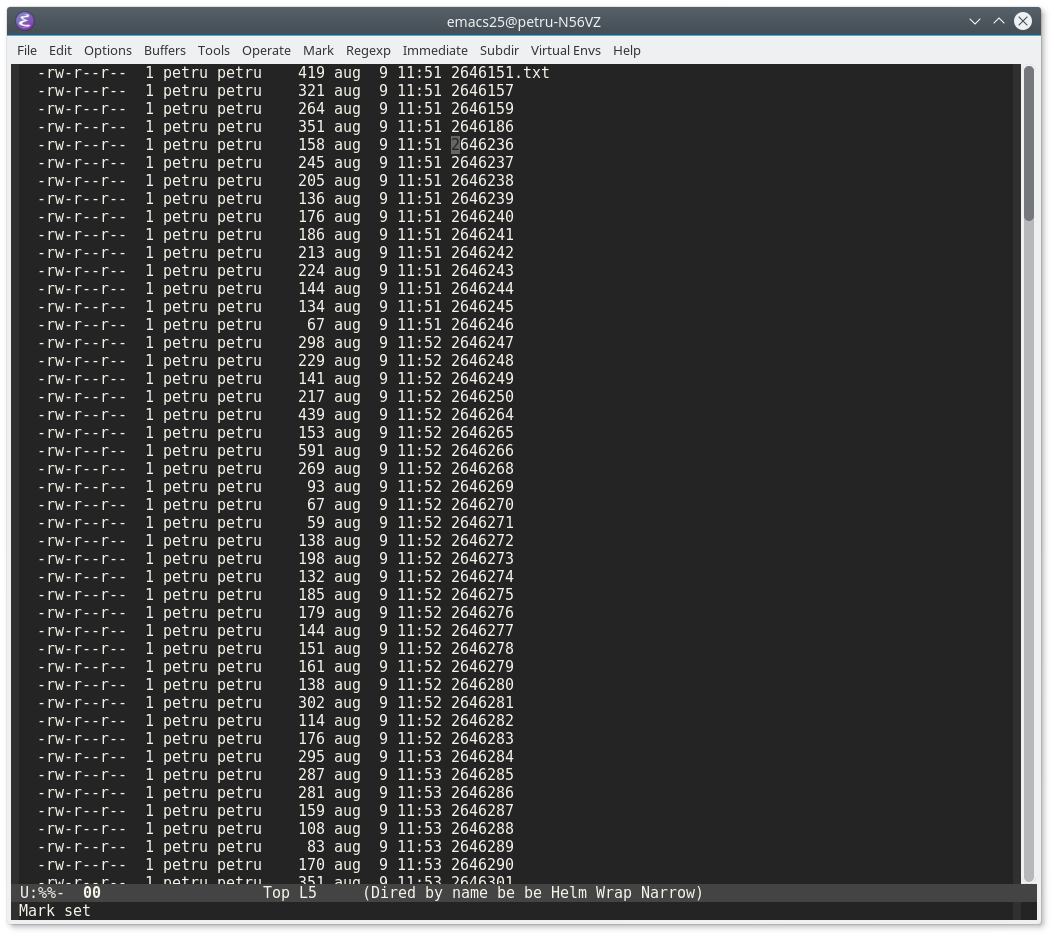
- Move to the beginning of buffer using
M-< - Start defining a new keyboard macro using
C-x (- Move to next line using
C-n - Navigate to the end of line using
C-e - Add the
.txtextension
- Move to next line using
- Save the macro with
C-x ) - Now that I have a macro to add
.txtextension to a file name I just need to run it as many times as there are unnamed files (100 in my case). To do so justC-u 100 F4. This will repeat the macro 100 times. - Once all the files are renamed exit the narrow-region using
M-x widenorC-x n w - Save changes with
C-c C-c
That's it!
Managing bibliography using Emacs Org-Mode and Org-Ref
Since I've started to use Emacs more and more I started wondering whether I can use org-mode to keep a reading list/bibliography?
A quick search led me to this blog post where the author was presenting his setup for the same thing. However, after reading into the post I saw that the author uses a combination of tasks and a reading list which requires custom code to be executed and is too complex for my needs.
All I want is a simple list that:
- should be available on multiple workstations
- can be built/managed with out-of-the-shelf components and without much effort
- should allow me to change the status of an entry.
I did however liked the idea of using references to the papers being read and since I recently saw a YouTube video presenting org-ref I thought I should give it a try.
To handle the availability part I decided to use Dropbox which is also suggested by org-ref.
Setup org-ref
org-ref is available on Melpa so to install it just type M-x package-install org-ref. Afterwards copy the code below to your init file and adjust the paths:
(setq reftex-default-bibliography '("~/Dropbox/bibliography/references.bib"))
;; see org-ref for use of these variables
(setq org-ref-bibliography-notes "~/Dropbox/bibliography/notes.org"
org-ref-default-bibliography '("~/Dropbox/bibliography/references.bib")
org-ref-pdf-directory "~/Dropbox/bibliography/bibtex-pdfs/")
(setq bibtex-completion-bibliography "~/Dropbox/bibliography/references.bib"
bibtex-completion-library-path "~/Dropbox/bibliography/bibtex-pdfs"
bibtex-completion-notes-path "~/Dropbox/bibliography/helm-bibtex-notes")
Creating the reading list
With org-ref in place, it was time to setup the reading list so I created a new file named reading-list.org under ~/Dropbox/bibliography/ with the following header:
#+TITLE: Reading list
#+STATUS: "Maybe" "Pending" "Reading" "Finished" ""
#+COLUMNS: %120ITEM %STATUS
The first line obviously defines the title of the document. The second line defines the values for status where:
-
Maybemeans that reading the entry is optional -
Pending- the entry will be read sometime after finishing the item that I'm currently reading -
Reading- the item currently being read -
Finished- the entries that are already read.
Adding an entry to the list
-
Add
bibtexentry inreferences.bibfile. E.g.:@inproceedings{le2014distributed, title={Distributed representations of sentences and documents}, author={Le, Quoc and Mikolov, Tomas}, booktitle={Proceedings of the 31st International Conference on Machine Learning (ICML-14)}, pages={1188--1196}, year={2014} }
- In the
reading-list.orgfile add the title to the list usingM-return - Add
StatusandSourceproperties- With the cursor on the header:
- Press
C-c C-x p - Select or write
Status - Press return
- Select the value for status (e. g.
Pending) - Press return
- Press
- With the cursor on the header:
- Press
C-c C-x p - Write or select
Source - Press return
- If you know the citation key (le2014distributed in the example above) then you can write directly
cite:le2014distributed; otherwise, leave the value forSourceempty and put the cursor after the property declaration. Then, pressC-c ]and select the entry from the reference list.
- Press
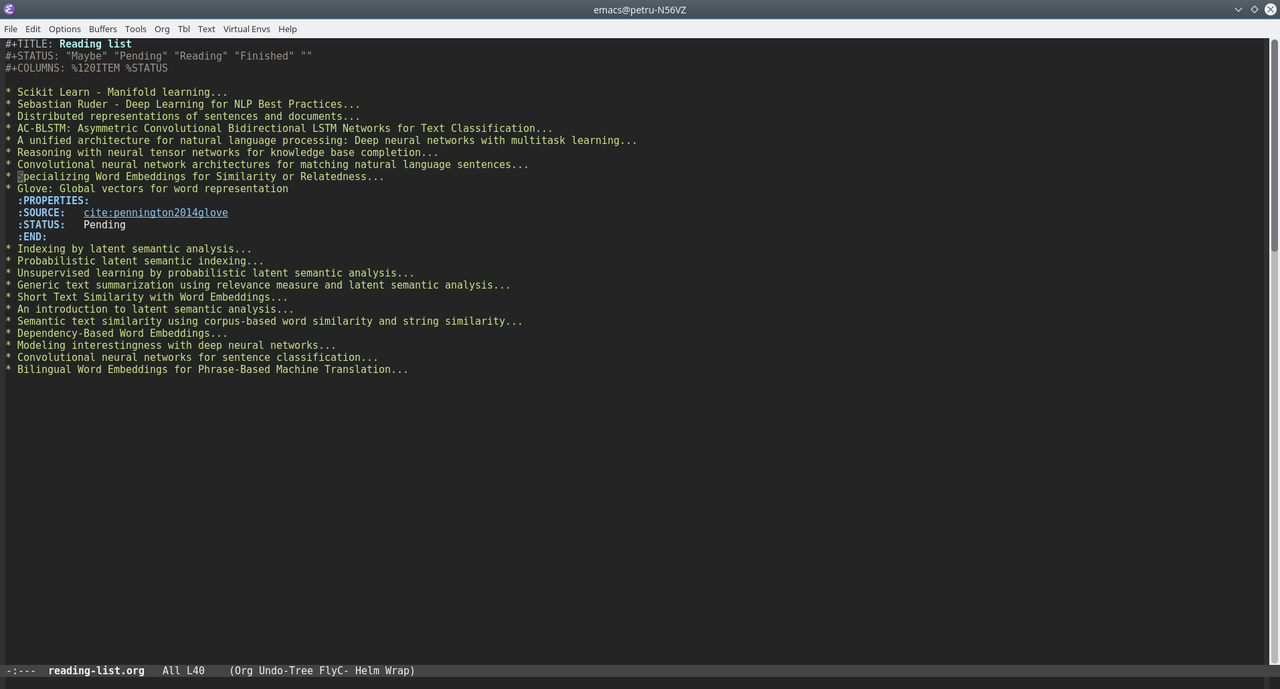
- With the cursor on the header:
Repeat the steps above and you should end up with a list like this:
Change the status of an entry
To change the status of an entry:
- Navigate to the desired entry
- Repeat the steps above for setting the
Statusproperty and select the proper value forStatus
Status overview
After creating the list you may want to have an overview of the status for each entry. This can be achieved using Org Column View.
The setup for column view is in the third line of the header
#+COLUMNS: %120ITEM %STATUS
which tells org-mode how to display the entries. Namely, we're defining two columns:
- Item which will display the heading on 120 characters and
- Status which will take as much space as needed to display the status
Switching to column view
To switch to column view, place the cursor outside the headings and press C-c C-x C-c (or M-x org-columns). The list should look like the image below:
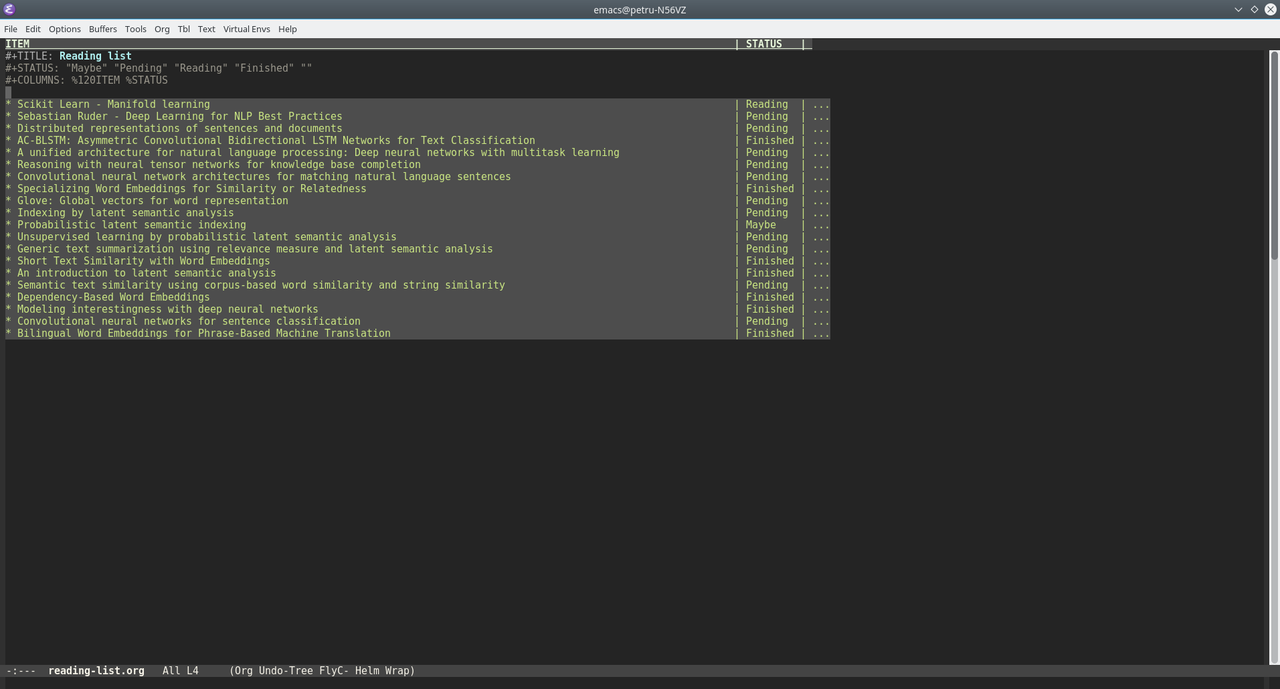 If your cursor was on a heading when pressing
If your cursor was on a heading when pressing C-c C-x C-c (invoking org-columns) then the column view will be activated only for the selected heading.
Exiting column view
To exit column view position the cursor on a heading that is currently in column view and press q.
That's it. Happy reading!
Adding Disqus comments to Ghost blog on Azure
If you have a Ghost hosted on Azure (like I did) then you may want to add Disqus comments to it (like I did).
To do so, follow the steps below:
- Create a Disqus account if you haven't done so already.
- Login to Disqus and navigate to the admin page.
- Click on Install Disqus and choose Ghost from the list.
- Open a new tab and navigate to Azure portal and from the dashboard open/navigate to the application hosting your Ghost blog.
- On the application blade select
App Service Editorand pressGo->to open the editor for your blog. - In the editor navigate to
wwwroot\content\themes\<your-theme>\post.hbs. This will load the file in the panel on the right. - Go back to Ghost Install Instructions on Disqus and copy the Universal Embed Code.
- Paste the code into post.hbs file in the place where you want your comment section to be.
-
Find the section to define configuration variables and make it look like this:
var disqus_config = function () { this.page.url = '{{@blog.url}}{{url}}'; this.page.identifier = '{{id}}'; };
Happy blogging!
Use Emacs sql-mode to connect to database on a Docker image
While working on a project I had to load and process some resources from a MySQL database. I had a database dump and all I needed was to sudo apt-get install mysql but I decided against it because that would just bloat my OS with software used only once and drain my laptop battery with the service running in the background.
Instead, I decided to restore the database on a Docker image for MySQL and query the data using mysql-client.
Install mysql-client locally
This one is simple; just run:
sudo apt-get install mysql-client
Install Docker on Ubuntu
The first thing to do is to head to Docker documentation for instalation instructions which I've copied here:
-
Install packages to allow
aptto use a repository over HTTPS:sudo apt-get install \ apt-transport-https \ ca-certificates \ curl \ software-properties-common
-
Add the official GPG key for Docker
curl -fsSL https://download.docker.com/linux/ubuntu/gpg | sudo apt-key add -
-
Setup the stable repository. Make sure to select the proper architecture; in my case it's
amd64sudo add-apt-repository \ "deb [arch=amd64] https://download.docker.com/linux/ubuntu \ $(lsb_release -cs) \ stable"
-
Update the package index
sudo apt-get update
-
Install Docker
sudo apt-get install docker-ce
Restore MySQL database to a Docker container
-
Download the Docker image for
MySQLsudo docker pull mysql
-
Create an empty database
sudo docker run --name <container-name> -e MYSQL_ROOT_PASSWORD=<password> -e MYSQL_DATABASE=<db-name> -d mysql
This will create a new container with an empty database and login
root. -
Restore database from dump
sudo docker exec -i <container-name> mysql -u<user-name> -p<password> --database=<db-name> < <path-to-sql-file>
Notes:
- Make sure that there is no space between
-uand<user-name>, e.g. for userrootthe option should be-uroot - The same goes for password - e.g. if password is
my-secretthen the option should be-pmy-secret -
path-to-sql-fileshould point to a file on host OS
- Make sure that there is no space between
Connect to MySQL database running on Docker container from Emacs
- First, start the container
sudo docker start <container-name> - Get the IP Address of the container
- Get the container configuration using
sudo docker inspect <container-name> - Copy the IP Address from the output under
NetworkSettings/IPAddress - In Emacs execute
M-x sql-mysql- For
User:enter the value for<user-name>(rootis the default) - For
Password:enter the value for<password> - For
Database:enter the value for<db-name> - For
Server:enter the IP Address from 2.
- For
That's it. Happy querying!
Editing remote files over ssh with Emacs and Tramp mode
In a discussion over a beer, a friend of mine asked whether I know a way to edit remote files over ssh? It was then that I realized that my long time obsession with Emacs is starting to pay off and I gave him the only way I know how to do that: Emacs and Tramp Mode.
This is how I do it.
Setup
I use Emacs 25.2 on Kubuntu 17.04 and on Windows 10 using Cygwin and when working with remote files both systems behave the same.
The flow
- Configure the remote machine to authenticate you with a key file as specified in this stackoverflow answer
- Start Emacs
To open the remote file for editing invoke the find-file command either using C-x C-f (C = Ctrl) or with M-x find-file (M=Alt) and at the file prompt specify the path in the following format:
/ssh:user@ip[:port]:path/to/file
An example
To exemplify let's consider the following scenario: I have a virtual machine with the IP 192.168.13.13 to which I can connect remotely with ssh using the username petru and the default public key (~/.ssh/idrsa.pub). On that machine I want to edit the file /home/petru/src/debugutils.py.
To do so, I open the file as usually in Emacs using C-x C-f and at the prompt (the minibuffer) I enter the following:
/ssh:petru@192.168.13.13:/home/petru/src/debugutils.py
and press <Enter>.
Using enums in C#
Recently Steve Smith posted an article named Enum Alternatives in C# where he points out that C# enums are nothing more than
simple value-type flags that provide very minimal protection from invalid values and no behavior
In the same article he mentiones type safe enum pattern as a better alternative to enums due to type safety. As a conclusion, Steve suggests that instead of using and declaring enums in the classical way
public enum WeekDay
{
Monday,
Tuesday,
Wednesday,
Thursday,
Friday,
Saturday,
Sunday
}
we should declare them in a type safe manner like this:
public class WeekDay
{
public static WeekDay Monday = new WeekDay(0, Resources.Monday);
public static WeekDay Tuesday = new WeekDay(1, Resources.Tuesday);
public static WeekDay Wednesday = new WeekDay(2, Resources.Wednesday);
public static WeekDay Thursday = new WeekDay(3, Resources.Thursday);
public static WeekDay Friday = new WeekDay(4, Resources.Friday);
public static WeekDay Saturday = new WeekDay(5, Resources.Saturday);
public static WeekDay Sunday = new WeekDay(6, Resources.Sunday);
private WeekDay(int value, string name)
{
Value = value;
Name = name;
}
public int Value { get; private set; }
public string Name { get; private set; }
}
This way the switch we all know and love (not) on the values of WeekDay will remain the same. Although this is a very elegant way of solving the issue of someone calling themeSelector.GetTheme((WeekDay)13) without getting an error from the compiler there are some issues with type safe enums:
- First of all,
type safe enumsarenullablewhich means that now we can callthemeSelector.GetTheme(null)and that would be a valid call which will most probably throw aNullReferenceExceptionwhen executed. - Second,
type safe enumscannot represent flags easily; they can by enumerating all possible values but that may not be an easy task for largeenums.
However, the problems the article refers to are not in the lack of compiler checks for valid enum values but rather how the enum values are used.
Displaying enums in UI elements
Let's look at the simplest problem Steve mentiones - displaying enum values in the UI. Indeed using the DescriptionAttribute is not the best solution you can have.
The biggest grudge I have with DescriptionAttribute is that it doesn't play nice with applications that have to support multiple languages. However, for the past few years (basically since extension methods were added to .NET Framework) I've taken another approach on displaying enum values in the UI.
The idea behind this is simple - build a Dictionary<TEnum, string> where the keys are enum values and values are localized strings taken from a resource file and bind the results to whatever control is used to display the enum. And for that I use a single extension method:
public static class EnumUtils
{
public static Dictionary<T, string> GetLocalizedEnumValues<T>(this ResourceManager resourceManager)
{
return Enum.GetValues(typeof(T))
.Cast<T>()
.Select(val => new { Value = val, Text = resourceManager.GetString(val.ToString()) })
.ToDictionary(kvp => kvp.Value, kvp => kvp.Text);
}
}
Of course, this method relies on a convention that the resource file must have entries for each enum value in order for it to work but when working with applications that support multiple languages there is seldom a case when something that needs to be displayed in the UI is not localized.
And now let's look at how this method can be used to localize enum values; as the example platform let's consider ASP.NET MVC:
public class ThemeController : Controller
{
public ActionResult Index()
{
var viewModel = new ThemeViewModel
{
WeekDays = Resources.ResourceManager.GetLocalizedEnumValues<WeekDay>()
.Select(kvp => new SelectListItem { Value = kvp.Key, Text = kvp.Value})
};
return View(viewModel);
}
}
Granted, it's more work to do in order to display enums like this but there are advantages:
-
No magic strings are involved compared to using
DescriptionAttribute - You have to do less repetitive work. If you declare your
enumin atype safemanner you'll have the tedious task of pairing eachenumvalue with its (localized) description by hand;GetlocalizedEnumValuesmethod will do that automatically for all enums which have entries in the resources file.
Use defensive coding in switch statements
Now, let's address the bigger issue when dealing with enums, namely calling (in our case) themeSelector.GetTheme((WeekDay)13). The problem here is that a lot of developers don't use defensive programming when dealing with enums (or at all).
Let's consider how our GetTheme method would look like in a non-defensive style and to emphasize things let's look at the worst-case scenario:
public class ThemeSelector
{
public Theme GetTheme(WeekDay weekDay)
{
switch(weekDay)
case WeekDay.Monday:
return new Theme { Playlist = "Monday mood" };
case WeekDay.Tuesday:
return new Theme { Playlist = "Four more days to Friday" };
case WeekDay.Wednesday:
return new Theme { Playlist = "It's hump day already!" };
case WeekDay.Thursday:
return new Theme { Playlist = "One more day!" };
case WeekDay.Friday:
return new Theme { Playlist = "Friday margueritas!" };
case WeekDay.Saturday:
return new Theme { Playlist = "Go away hangover!" };
case WeekDay.Sunday:
default: // BAD!!!
return new Theme { Playlist = "There's still time to party!" };
}
}
See the problem there? The developer assumes that the method will always receive a valid value thus he/she links the default case with an existing label instead of checking the value.
The simplest fix for this is below:
public class ThemeSelector
{
public Theme GetTheme(WeekDay weekDay)
{
switch(weekDay)
case WeekDay.Monday:
return new Theme { Playlist = "Monday mood" };
case WeekDay.Tuesday:
return new Theme { Playlist = "Four more days to Friday" };
case WeekDay.Wednesday:
return new Theme { Playlist = "It's hump day already!" };
case WeekDay.Thursday:
return new Theme { Playlist = "One more day!" };
case WeekDay.Friday:
return new Theme { Playlist = "Friday margueritas!" };
case WeekDay.Saturday:
return new Theme { Playlist = "Go away hangover!" };
case WeekDay.Sunday:
return new Theme { Playlist = "There's still time to party!" };
default:
throw new ArgumentException("Invalid value for WeekDay enum.");
}
}
Throwing the ArgumentException when receiving an invalid value will crash the application but this crash gives us at least two benefits:
- The application behavior becomes predictable:
GetThememethod will either return a validThemeor will throw an error - It makes debugging a lot easier; you know the point of failure, you know the reason and you have the full stack trace. When the application crashes twenty steps after receiving the invalid value there are a lot more unknows to why the application crashed and it may be harder to reproduce the problem.
Use specialzed builders instead of switch statements
However, the best way to use switch statements is to avoid it altoghether. Why? Mainly because switch statements are the main violators of Open/Closed Principle i.e.every time a new member of the enum is added, every switch on that enum values needs to be changed in order to accomodate the new member (except for the cases that use the default label).
In such cases I prefer to use something that I call specialized builders to avoid the switch statement.
The ideea is simple: the logic behind each label of the switch statement is refactored into a separate class which implements a common interface for all the labels. The same interface exposes a property of the enum type which tells the clients of the interface which enum value it can process. The client code receives as a dependency a collection of such instances and instead of a switch statement it just iterates through the collection to find the suitable instance.
Let's exemplify using our scenario; instead of having the switch statement inside the GetTheme method from the previous example, let's refactor each labels logic into a separate class. But before that, let's define an interface that will be implemented by all the classes.
Since the switch is used to build instances of Theme class, let's call the interface IThemeBuilder; here is it's definition:
public interface IThemeBuilder
{
WeekDay WeekDay { get; }
Theme BuildTheme();
}
Now an implementation of this interface for WeekDay.Monday would look like this:
public class MondayThemeBuilder
{
public WeekDay WeekDay
{
get { return WeekDay.Monday; }
}
public Theme BuildTheme()
{
return new Theme { Playlist = "Monday mood" };
}
}
With all the implementations in place, all it remains to do is to register the implementations of IThemeBuilder interface in the DI container and inject them into the ThemeSelector class. The GetTheme method now becomes an iteration to find a suitable builder for the argument received. If no such instance is found, an exception is thrown to signal the error.
public class ThemeSelector
{
private readonly IEnumerable<ThemeBuilder> builders;
public ThemeSelector(IEnumerable<IThemeBuilder> themeBuilders)
{
builders = themeBuilders;
}
public Theme GetTheme(WeekDay weekDay)
{
var builder = builders.SingleOrDefault(b => b.WeekDay == weekDay);
if( builder == null)
throw new ArgumentException(String.Format("Invalid value '{0}' received for week day.", weekDay));
return builder.BuildTheme();
}
}
Now everytime a new member needs to be added to WeekDay enum, although not the case here, there are at most three changes to make to accomodate the new value:
- Add the new value to the
enum - Create a new class that will implement
IThemeBuilderfor the new value - Register the new class in the
DI container
Depending on which dependency injection library you use, there may be no change required for registering the new class in the container.
Conclusions
The main conclusion of the article is that enums aren't bad they're just improperly used. Sometimes creating a thick class to represent type safe enums may be suitable for your scenario but most of the time it's not worth the effort. Instead, you should concentrate more on the places in code where the enum is used to make them safer, more clean and elegant.
Abstraction is not a principle of Object Oriented Programming
TL;DR
Abstraction is a core concept in programming and not a principle that is solely applicable in OOP, because programming is all about dealing with an abstract representation of the business model (application space).
Abstraction is an overall programming principle
There are a lot of articles saying that OOP has four principles:
EncapsulationInheritancePolymorphismAbstraction
But if we do a web searh for what is abstraction? we get more or less the same definition as the one from here.
Abstraction (from the Latin abs, meaning away from and trahere, meaning to draw) is the process of taking away or removing characteristics from something in order to reduce it to a set of essential characteristics.
Although the article defines abstraction in an OOP context, abstraction is actually a an overall programming principle.
Why? Because programming means modeling entities and interactions of an abstract representation of the business model. And since there are several programming paradigms all of which are used to represent a set of specific business models all of those paradigms use abstraction to succeed in that representation.
An example of abstraction in OOP
To better clarify what abstraction is (in OOP) let's consider a trivial example: A StudentRegistrationController (ASP.NET MVC) needs to save the data from a registration form (Student) into some sort of database represented by an instance of IStudentDataStore.
For the sake of brevity let's say that IStudentDataStore interface has the following definition:
public interface IStudentDataStore
{
void Save(Student student);
}
With that in mind, the code for the example above would look like this:
public class Student
{
public string FirstName { get; set; }
public string LastName { get; set; }
public DateTime DateOfBirth { get; set; }
public Gender Gender { get; set; }
public string Email { get; set; }
public string PhoneNumber { get; set; }
}
public class StudentRegistrationController : Controller
{
public StudentRegistrationController(IStudentDataStore dataStore)
{
_dataStore = dataStore;
}
public ActionResult Save(Student viewModel)
{
// Validation ommited for brevity
_dataStore.Save(viewModel);
}
}
As we can see from the code the IStudentDataStore abstracts the details of how Student data is persisted. The interface doesn't tell whether the data is persisted to a flat file, SQL Database, NoSQL database or other media. As long as we have an implementation of IStudentDataStore the controller works just fine.
But is this abstraction technique available only in OOP paradigm? The answer is no. The same thing, although in a different form can be used in other paradigms. To demonstrate so, let's use lisp as a programming language and let's see how abstraction works in a functional programming paradigm.
The same example of abstraction in functional programming
To see how the same thing would be written in a functional style let's first see what are the entities from the previous example and how those entities interact between them:
-
StudentRegistrationController- Is the top-most entity
- Has an
IStudentDataStoreon which calls theSavemethod
-
IStudentDataStore- Defines a contract between the controller and the underlying data store
-
Student- Is a data contract, i.e. encapsulates all the properties of a student into a single entity
Having the above and knowing that in functional programming everything is a function we replace every entity with a function:
- We'll create a top-level function named
save-student; it will have the following parameters:-
student-info-> a hash map containing the data contract -
persist-func-> a function that will be called to save the data to a data store
-
- Another two functions
persist-student-info-to-fileandpersist-student-info-in-memorywill encapsulate the logic of persisting data to a data store.
Note that both functions have the same signature. The parameters of these functions represent the data contract.
(defun persist-student-info-to-file (first-name last-name dob gender email phone)
;; Writes the info as a new line into the file specified by *database-location*
(let ((stream (open *database-location*
:direction :output
:if-exists :append)))
(format stream "~s|~s|~s|~s|~s|~s"
first-name
last-name
dob
gender
email
phone)
(close stream)))
(defun persist-student-info-in-memory (first-name last-name dob gender email phone)
;; Persists student data into an in-memory data store named *all-students*
(let ((student-id (list-length *all-students*)))
(setq *all-students*
(append *all-students*
(list student-id first-name last-name dob gender email phone)))))
(defun save-student (student-info persist-func)
;; Saves student data to a persistent store
(let ((first-name (gethash 'first-name student-info))
(last-name (gethash 'last-name student-info))
(dob (gethash 'date-of-birth student-info))
(gender (gethash 'gender student-info))
(email (gethash 'email student-info))
(phone (gethash 'phone-number student-info)))
(funcall persist-func first-name last-name dob gender email phone)))
Having the definitions above we can achieve the same level of abstraction by putting everything together and defining global variables (think of it as poor mans dependency injection):
(defparameter *database-location* "/tmp/students")
(defparameter *student-info* (make-hash-table))
(progn
(setf (gethash 'first-name *student-info*) "John")
(setf (gethash 'last-name *student-info*) "Doe")
(setf (gethash 'date-of-birth *student-info) "2000-05-14")
(setf (gethash 'email *student-info*) "john.doe@example.com")
(setf (gethash 'phone-number *student-info*) "1234567981"))
(save-student *student-info* 'persist-student-info-to-file)
Et voilà! We have used abstraction in a functional style to remove the details of how the data is persisted thus showing that abstraction isn't a principle applicable only to object oriented programming.
Acknowledgments
A big thank you to Ion Cojocaru and Florin Olariu who reviewed this post before publication.
FII Practic 2016
Programming principles
Chapter I - Object Oriented Programming
Encapsulation
Encapsulation facilitates bundling of data with the method(s) operating on that data.
To exemplify let's consider the following requirement: As an account holder I want to perform withdrawal and deposit of various amounts from and into my account.
To implement the requirement we consider the following:
- An
Accounthas aBalance - A
Withdrawalis an operation which subtracts theamountfrom theBalance - A
Depositis an operation which adds theamountto theBalance
The code below should do it:
public class Account
{
public Money Balance { get; set; }
}
public class Program
{
static void Main(string[] args)
{
var account = new Account();
// Make a deposit
account.Balance += 50;
// Withdraw some cash
account.Balance -= 100;
}
}
Houston, we have a problem. If we let the consumers of our code (in this case Program) to change the Balance at will, our system may end up in such funky situations where account holders can withdraw as much money as they want from the ATM without having enough funds.
Of course, we need to validate each withdrawal but we can't surround each account.Balance -= amount with an if(account.Balance > amount) because it's time consuming, inefficient
and we simply may not have access to the code that uses our class. What we can do is to encapsulate the withdrawal and validation into a single operation like this:
public class Account
{
public Money Balance {get; private set; } // The balance is now read-only
public Money Withdraw(Money amount)
{
if( Balance <= amount)
{
throw new InvalidOperationException("Insufficient funds.");
}
this.Balance -= amount;
return amount;
}
public void Deposit(Money money)
{
this.Balance += money;
}
}
public class Program
{
static void Main(string[] args)
{
var account = new Account();
account.Deposit(50);
account.Withdraw(100); // => InvalidOperationException.
}
}
Much better! Now we are in control and we can be sure that every withdrawal is validated against account balance. As a nice side effect our code gains readability.
Inheritance and Polymorphism
Inheritance is the ability of a new class to acquire the properties of another class.
Let's look at another requirement:
As an account holder I can have multiple accounts of various types such as savings account, debit account etc for which different withdrawal fees apply. For a debit account the withdrawal fee is zero; for a savings account the withdrawal fee is 0.5% of the amount withdrawn.
From the requirement we can deduct that an Account can be modeled as a class with two properties - a Balance and a Type which can take values from an enumeration.
Also, additional changes to the Withdraw method should be applied:
- Each withdrawal calculates and subtracts a fee from the balance
- The check for insufficient funds should also take into the consideration the fee alongside the amount
Given the above, our code would look like this:
public enum AccountType
{
Debit,
Savings
}
public class Account
{
private readonly AccountType _accountType;
public Account(AccountType accountType)
{
_accountType = accountType;
}
public AccountType AccountType { get { return _accountType; } }
public Money Balance { get; private set; }
public void Deposit(Money money)
{
this.Balance += money;
}
public Money Withdraw(Money amount)
{
var fee = CalculateWithdrawalFee(amount);
amount = amount + fee;
if( Balance <= amount)
{
throw new InvalidOperationException("Insufficient funds.");
}
this.Balance -= amount;
}
private Money CalculateWithdrawalFee(Money amount)
{
var margin = _accountType == AccountType.Savings ? 0.5 : 0;
return amount * margin / 100;
}
}
Everything looks good except the magic numbers. Until we get a new requirement:
As an account holder I can have a credit account with a withdrawal fee of 0.7%
To accomodate this new requirement we just have to change the CalculateWithdrawalFee method and add a new value in our AccountType enum:
public enum AccountType
{
Debit,
Savings,
Credit
}
...
private Money CalculateWithdrawalFee(Money amount)
{
switch( _accountType )
case AccountType.Savings:
return amount * 0.5 / 100;
case AccountType.Credit:
return amount * 0.7 / 100;
default:
return 0;
}
The problem with this approach is that we had to add changes in more than one place; and the hint that this way of implementing the new requirement is not ok was given by the
and conjunction from the previous sentence. And if that wasn't enough then the switch should be the indicator of a possible code smell.
A better way to address these requirements is through inheritance by first determining which are the common traits of an Account and extracting them into a base class followed by modeling the specific behavior for each
subsequent type of account into its separate class.
So, as before, the common traits of an account are:
- All accounts have a
Balanceproperty - All accounts support
WithdrawalandDeposit - All accounts validate available amount when a withdrawal is performed
The distinct traits of the accounts are:
- Savings accounts have a withdrawal fee of 0.5% of the amount withdrawn
- Credit accounts have a withdrawal fee of 0.7% of the amount withdrawn
- Debit accounts don't have a withdrawal fee
Although we can see a clear difference between the common traits and specific features for each account type there is a certain amount of overlapping between them when performing a withdrawal. In other words and specifically for withdrawal operation we can say that:
- All account types support withdrawal
- Each account type applies a specific withdrawal fee
- All account types validate the amount against available funds
In order to model such kind of mixture between common and specific behavior we can make use of polymorphism by defining an abstract method CalculateWithdrawalFee which will be overridden
in the derived classes with specific values for each account type but still keeping the common behavior in a single place.
Now, with this approach let's address each requirement in the order they arrived. First, let's create the base class:
public abstract class Account
{
public Money Balance { get; private set; }
public void Deposit(Money money)
{
this.Balance += money;
}
public Money Withdraw(Money amount)
{
var fee = CalculateWithdrawalFee(amount);
amount = amount + fee;
if( Balance <= amount)
{
throw new InvalidOperationException("Insufficient funds.");
}
this.Balance -= amount;
}
protected abstract Money CalculateWithdrawalFee(Money amount);
}
With the base class in place, let's model the first two account types - debit and savings:
public class DebitAccount : Account
{
protected override Money CalculateWithdrawalFee(Money amount)
{
return 0;
}
}
public class SavingsAccount : Account
{
protected override Money CalculateWithdrawalFee(Money amount)
{
return amount * 0.5 / 100;
}
}
With this structure in place adding a new account type is as simple as adding a new derived class and all edits are in a single place - the newly added file:
public class CreditAccount : Account
{
protected override Money CalculateWithdrawalFee(Money amount)
{
return amount * 0.7 / 100;
}
}
Chapter II - Structure
How you structure your code is very important in software development. A good code structure promotes low coupling and high cohesion which is a must for all good software.
Let's take a look at what coupling and cohesion mean.
Low coupling - The case of the Singleton
To exemplify what low coupling is and its importance let's take a look at the well-kown Singleton pattern:
public class FileSystem
{
private static readonly FileSystem _root = new FileSystem();
private FileSystem()
{
}
public static FileSystem Root
{
get { return _root; }
}
public string[] List(string path)
{
return Directory.EnumerateDirectories(path)
.Union(Directory.EnumerateFiles(path))
.ToArray();
}
}
public class Explorer
{
public string CurrentDirectory { get; set; }
public IEnumerable<string> Contents { get; private set;}
public void NavigateTo(string path)
{
var contents = FileSystem.Root.List(path);
CurrentDirectory = path;
Contents = contents;
foreach(var item in contents)
{
Display(item);
}
}
}
public class Program
{
static void Main(string[] args)
{
var explorer = new Explorer();
explorer.NavigateTo(@"c:\users\petru\Documents\");
}
}
What is wrong in the code above? The Explorer class is tightly coupled with FileSystem singleton, i.e. Explorer class is highly denendent on the FileSystem class and cannot be used without the FileSystem.
To demonstrate this tight coupling let's create a test for Explorer class to verify that it returns proper values from a known directory:
public class ExplorerTests
{
protected string Directory { get; set; }
protected Explorer Explorer { get; private set;}
protected void Initialize()
{
Explorer = new Explorer();
}
[TestClass]
public class WhenNavigatingToTempDirectory : ExplorerTests
{
[TestInitialize]
public void TestInitialize()
{
Initialize();
Directory = @"C:\Temp\";
}
[TestMethod]
public void ShouldDisplayDirectoryContents()
{
Explorer.NavigateTo(Directory);
Assert.AreEqual(Directory, Explorer.CurrentDirectory);
Assert.AreEqual("C:\Temp\test.txt", Explorer.Contents.Single());
}
}
}
This test may succeed on our machine because we know that there's a file named text.txt in our C:\Temp\ directory because we've put it there. But what if we execute that test on another machine? Will that file be there?
Having such code means that not only our Explorer class is tightly coupled with the FileSystem class but also that this chain of dependency can grow to depend on the contents of the machine it's running on. We'll see how to break this dependecies in Chapter III - SOLID code.
High cohesion - Why can't I have all code in Program.cs?
Cohesion refers to the degree to which the elements of a module belong together.
The main reason for properly structuring your application is that similar entities belong toghether.
Let's consider the previous example in a less cohesive form:
public class Program
{
static void Main(string[] args)
{
NavigateTo(@"C:\users\petru\Documents\");
}
static void NavigateTo(string path)
{
var contents = Directory.EnumerateDirectories(path)
.Union(Directory.EnumerateFiles(path));
foreach(var item in contents)
{
Display(item);
}
}
}
In this case our Program is nothing more than a God object - it does everything and this is a problem. It may not be a problem for such a trivial application but when it comes to real applications things get more complicated.
Even small production applications have a lot of objects and that number keeps growing alongside the growth of the application and at some point having everything in one place is simply unbearable. Furthermore, chances are that more than one developer will be working on the same codebase and you can't just have everything in a single file.
Chapter III - SOLID code
Single Responsibility Principle
Let's look again at our Account example:
public abstract class Account
{
public Money Balance { get; private set; }
public void Deposit(Money money)
{
this.Balance += money;
}
public Money Withdraw(Money amount)
{
var fee = CalculateWithdrawalFee(amount);
amount = amount + fee;
if( Balance <= amount)
{
throw new InvalidOperationException("Insufficient funds.");
}
this.Balance -= amount;
}
protected abstract Money CalculateWithdrawalFee(Money amount);
}
As you can see from the code, the Withdraw method does more than one thing, namely:
- It calculates the withdrawal fee
- It subtracts the amount and withdrawal fee from the balance
The purpose of this method is to withdraw the amount from the available balance; calculating the withdrawal fee should be someone else's responsibility. And that someone else should be a WithdrawalAmountCalculator:
public class WithdrawalAmountCalculator
{
public Money CalculateWithdrawalAmount(Money amount, decimal percentage)
{
return amount * percentage / 100;
}
}
Now, let's put it all together and remove the extra responsibilities from Account class:
public class WithdrawalAmountCalculator
{
public Money CalculateWithdrawalAmount(Money amount, decimal feePercentage)
{
return amount * feePercentage / 100;
}
}
public abstract class Account
{
private readonly WithdrawalAmountCalculator _amountCalculator;
protected Account(WithdrawalFeeCalculator amountCalculator)
{
_amountCalculator = amountCalculator;
}
public Money Balance { get; private set; }
public abstract decimal WithdrawalInterestRate { get; }
public void Deposit(Money money)
{
this.Balance += money;
}
public Money Withdraw(Money amount)
{
var amountToWithdraw = _amountCalculator.CalculateWithdrawalAmount(amount, WithdrawalInterestRate);
if( Balance <= amountToWithdraw)
{
throw new InvalidOperationException("Insufficient funds.");
}
this.Balance -= amountToWithdraw;
return amount;
}
}
public class DebitAccount : Account
{
public DebitAccount(WithdrawalAmountCalculator amountCalculator) : base(amountCalculator)
{
}
public override decimal WithdrawalInterestRate
{
{ get { return 0m; }}
}
}
public class Program
{
static void Main(string[] args)
{
var calculator = new WithdrawalAmountCalculator();
var account = new DebitAccount(calculator);
account.Deposit(new Money(100));
var cash = account.Withdraw(50);
}
}
Much better! Each class does only one thing, namely:
-
WithdrawalAmountCalculatorcalculates the withdrawal amount and -
Accounthandles the changes to balance.
Open/Closed principle
Let's go back again to a previous example, the one with multiple account types:
public enum AccountType
{
Debit,
Savings,
Credit
}
...
private Money CalculateWithdrawalFee(Money amount)
{
switch( _accountType )
case AccountType.Savings:
return amount * 0.5 / 100;
case AccountType.Credit:
return amount * 0.7 / 100;
default:
return 0;
}
The code from the example above is the exact opposite of Open/Closed principle:
- It is open for modification because every time we'll need to create a new account type we'll have to add another
caseto theswitchstatement withinCalculateWithdrawalAmountmethod - It is closed for extension in the sense that even if we do create a derived type of
Accountthat type will have to always take into consideration theAccountTypeproperty when implementing its custom behavior.
Liskov substitution principle
To exemplify let's consider the overused Rectangle and Square example where one would model the relationship between them using the following statement: a Square is a Rectangle having Width == Height as behavioral description. In other words, a Square behaves exactly like a Rectangle but the Square has Width == Heigth.
As an object hierarchy this would look like the following:
public class Rectangle
{
protected int _width;
protected int _height;
public virtual int Width
{
get { return _width; }
set { _width = value; }
}
public virtual int Height
{
get { return _height; }
set { _height = value; }
}
}
public class Square : Rectangle
{
public override int Width
{
get { return _width; }
set
{
_width = value;
_height = value;
}
}
public override int Height
{
get { return _height; }
set
{
_height = value;
_width = value;
}
}
}
Now let' think of consumer of this code: it knows it's working with a Rectangle and sets all the values accordingly but it is given a Square to work with. Let's see that in code:
public class Program
{
private const int ImageWidth = 800;
private const int ImageHeight = 600;
static void Main(string[] args)
{
var rectangle = new Square();
InitializeRectangle(rectangle);
var area = rectangle.Width * rectangle.Height;
Debug.Assert(area == ImageWidth * ImageHeight);
}
void InitializeRectangle(Rectangle rectangle)
{
rectangle.Width = ImageWidth;
rectangle.Height = ImageHeight;
}
}
The method InitializeRectangle will perform it's work on a Rectangle thus will set its Width and Height properties and the Main method will be expecting to have an rectangle with the area of ImageWidth * ImageHeight but since the Square overrides the Width when Height is set (and viceversa) the actual area of the rectangle will be ImageHeight * ImageHeight.
This shows that although a Square may have a similar structure with an Rectangle it cannot be used as a substitute for a Rectangle because it doesn't have the same behavior.
Interface Segregation principle
Many client-specific interfaces are better than one general-purpose interface.
To exemplify this let's consider some existing types within .NET Framework: MembershipProvider from System.Web.Security namespace and IUserStore from Microsoft.AspNet.Identity namespace:
public abstract class MembershipProvider : ProviderBase
{
public abstract bool EnablePasswordRetrieval { get; }
public abstract bool EnablePasswordReset { get; }
public abstract bool RequiresQuestionAndAnswer { get; }
public abstract string ApplicationName { get; set; }
public abstract int MaxInvalidPasswordAttempts { get; }
public abstract int PasswordAttemptWindow { get; }
public abstract bool RequiresUniqueEmail { get; }
public abstract MembershipPasswordFormat PasswordFormat { get; }
public abstract int MinRequiredPasswordLength { get; }
public abstract int MinRequiredNonAlphanumericCharacters { get; }
public abstract string PasswordStrengthRegularExpression { get; }
public event MembershipValidatePasswordEventHandler ValidatingPassword
public abstract MembershipUser CreateUser(string username, string password, string email, string passwordQuestion, string passwordAnswer, bool isApproved, object providerUserKey, out MembershipCreateStatus status);
public abstract bool ChangePasswordQuestionAndAnswer(string username, string password, string newPasswordQuestion, string newPasswordAnswer);
public abstract string GetPassword(string username, string answer);
public abstract bool ChangePassword(string username, string oldPassword, string newPassword);
public abstract string ResetPassword(string username, string answer);
public abstract void UpdateUser(MembershipUser user);
public abstract bool ValidateUser(string username, string password);
public abstract MembershipUser GetUser(object providerUserKey, bool userIsOnline);
public abstract MembershipUser GetUser(string username, bool userIsOnline);
internal MembershipUser GetUser(string username, bool userIsOnline, bool throwOnError)
public abstract string GetUserNameByEmail(string email);
public abstract bool DeleteUser(string username, bool deleteAllRelatedData);
public abstract MembershipUserCollection GetAllUsers(int pageIndex, int pageSize, out int totalRecords);
public abstract int GetNumberOfUsersOnline();
public abstract MembershipUserCollection FindUsersByName(string usernameToMatch, int pageIndex, int pageSize, out int totalRecords);
public abstract MembershipUserCollection FindUsersByEmail(string emailToMatch, int pageIndex, int pageSize, out int totalRecords);
protected virtual byte[] EncryptPassword(byte[] password)
protected virtual byte[] EncryptPassword(byte[] password, MembershipPasswordCompatibilityMode legacyPasswordCompatibilityMode)
protected virtual byte[] DecryptPassword(byte[] encodedPassword)
protected virtual void OnValidatingPassword(ValidatePasswordEventArgs e)
}
public interface IUserStore<TUser, in TKey> : IDisposable where TUser : class, IUser<TKey>
{
Task CreateAsync(TUser user);
Task UpdateAsync(TUser user);
Task DeleteAsync(TUser user);
Task<TUser> FindByIdAsync(TKey userId);
Task<TUser> FindByNameAsync(string userName);
}
public interface IUserPasswordStore<TUser, in TKey> : IUserStore<TUser, TKey>, IDisposable where TUser : class, IUser<TKey>
{
Task SetPasswordHashAsync(TUser user, string passwordHash);
Task<string> GetPasswordHashAsync(TUser user);
Task<bool> HasPasswordAsync(TUser user);
}
If we would have to implement a simple authentication mechanism the functionality of IUserStore and IUserPasswordStore would be sufficient for our needs. Compare implementing only the functionality required for these two interfaces with the effort required to derive from the MembershipProvider class. Even worse, I can say from my experience that with the MembershipProvider you'll be writing code which will never be used.
Dependency Inversion principle
Let's go back to our Singleton example. In the previous module we stated that the Explorer class is tightly coupled with the FileSystem class thus depending on it and also depending on underlying file system for tests to succed.
To break this dependency we need to hide the functionality of our FileSystem behind an abstraction and we do that using an interface IFileSystem which will be implemented by FileSystem class:
public interface IFileSystem
{
string[] List(string path);
}
public class FileSystem : IFileSystem
{
public string[] List(string path)
{
return Directory.EnumerateDirectories(path)
.Union(Directory.EnumerateFiles(path))
.ToArray();
}
}
Now we make the Explorer class depend upon the IFileSystem interface:
public class Explorer
{
private readonly IFileSystem _fileSystem;
public Explorer(IFileSystem fileSystem)
{
_fileSystem = fileSystem;
}
public string CurrentDirectory { get; set; }
public IEnumerable<string> Contents { get; private set;}
public void NavigateTo(string path)
{
var contents = _fileSystem.Root.List(path);
CurrentDirectory = path;
Contents = contents;
foreach(var item in contents)
{
Display(item);
}
}
}
Now it's up to the Program class to glue them together:
public class Program
{
static void Main(string[] args)
{
var fs = new FileSystem();
var explorer = new Explorer(fs);
explorer.NavigateTo(@"c:\users\petru\Documents\");
}
}
This way we can test the Explorer class separately from the FileSystem class by passing it an instance of a class that implements IFileSystem and returns some stub data.
As an additional bonus, the semantics of the Singleton is still in place - there is only one instance of the FileSystem class for the whole lifetime of the application.